記事一覧
ブログ(無料版)の仕様で、デフォルトのトップページだと投稿記事の1つ1つが全部表示されてしまい、ブログ全体を把握しづらい。下記のリンクから入ったほうが記事を探しやすいかも。このブログをブックマークする際も下記リンクをブックマークすることをオススメする。
ブログ(無料版)の仕様で、デフォルトのトップページだと投稿記事の1つ1つが全部表示されてしまい、ブログ全体を把握しづらい。下記のリンクから入ったほうが記事を探しやすいかも。このブログをブックマークする際も下記リンクをブックマークすることをオススメする。
以前、ポータブックにインストールしたUbuntu18.04のサポート期間が2023年4月まででサポートが切れてしまったので、Lubuntu24.04をインストールする方法。
普通にLubuntu24.04のLiveUSBメモリを作成して、ポータブックにインストールしようとしても、LiveUSBからはsafe graphicsモード(nomodeset)でしかLive起動してくれず、かつ、それでインストールされたLubuntuはsafe graphics(nomodeset)では立ち上がってくれないので、ブラックアウトになって起動に失敗する。
なら、インストール前のISOをカスタムして、インストールされるLubuntuをデフォルトでsafe graphics(nomodeset)で立ち上がるようすればよい。
そこで、Ubuntu系のISOイメージをカスタムできる「Cubic(Custom Ubuntu ISO Creator)」を使って、カスタムISOイメージを作成する。
CubicでカスタムISOを作成するためには、ポータブックとは別の、UbuntuのPC(以下、母艦Ubuntuとする)が必要。
GitHub - PJ-Singh-001/Cubic: The Official Web Site for Cubic (Custom Ubuntu ISO Creator) を参考に、母艦UbuntuにCubicをインストール。
端末で以下を1行ずつ実行。
sudo apt-add-repository universe
sudo apt-add-repository ppa:cubic-wizard/release
sudo apt update
sudo apt install --no-install-recommends cubic
Lubuntu公式サイトからLubuntu24.04のISOイメージをダウンロード。
Cubicを起動
→プロジェクトディレクトリ(カスタムISOイメージができるディレクトリ)を選択してNEXT
→Volume IDを「Lubuntu 24.04 LTS」に変更(デフォルトの長い名前だと、後述のconkyで表示される際に長くなってしまうので。conkyを使わないのであれば、必須ではない。)
→「Customize the Linux file system using the virtual environment terminal.」というターミナル画面になるので、
(※sudoは付けない)
nano /etc/default/grub
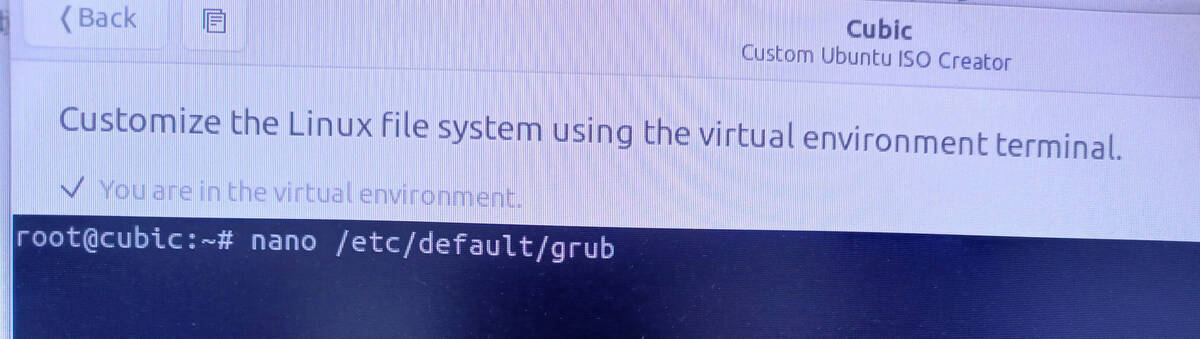
で以下のような画面になるので、「"quiet splash"」の行のところに nomodeset を追加して、次のようになるように入力、
"quiet splash nomodeset"
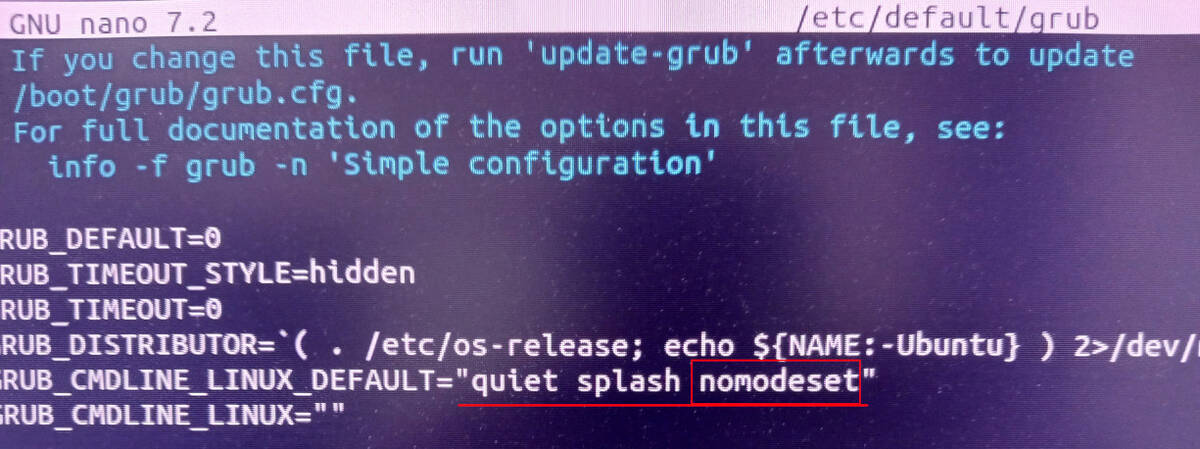
上書き保存する(Ctrl+O、「File Name to Write: /etc/default/grub」と出てきたらエンター。Ctrl+Xでnanoを終了)。
インストール後すぐに日本語入力ができるように、日本語入力環境も含めておく。
apt install fcitx-mozc mozc-utils-gui
「NEXT」を繰り返しクリックしていく。
「Make changes to advanced options on the tabs above,or proceed with default settings.」 の画面に進んだら、「Boot」のタブをクリック。
「grub.cfg」の
menuentry "Lubuntu (safe graphics)" {
set gfxpayload=keep
linux /casper/vmlinuz boot=casper nomodeset --- quiet splash
initrd /casper/initrd.gz
}
を menuentry "Try or Install Lubuntu" { の行の上に移動させる。
つまり、grubメニューで"Lubuntu (safe graphics)"が一番上に来るようにする。
「loopback.cfg」も同様にする。
「NEXT」をクリックしていき、カスタムISOの完成。
「ブータブルUSBの作成」(UbuntuでLiveUSBメディア作成)でUSBメモリに、出来上がったカスタムISOイメージを入れていく。
ポータブックにLiveUSBメモリを挿して、起動、F2ボタンを連打して、ブートメニューにして、LiveUSBメモリを選択。
そして、grubメニューで
Lubuntu(safe graphics)
を選んで、エンター。
インストール画面が表示されるので、日本語に設定したら、あとは普通にインストールしていく。
インストールが終わって、ポータブックを起動し直したら、無事、Lubuntuが立ち上がるはず。
WiFiを設定してネットにつなげたら、何はともあれ端末(メニュー>システムツール>Qterminal)で以下を実行。
sudo apt update && sudo apt upgrade
18.04の時にあった音声が出ないということはなく、普通に音声は出るのだが、YouTube動画や音楽ファイルを再生していると、しばらくすると、音が途切れて、ビィーっという大きな音が鳴り出すというバグがある。
その対策のために、端末を開いて、
sudo nano /etc/modprobe.d/alsa-base.conf
alsa-base.confの最後に以下を追記して、保存。
# Enables sof debug mode, resolves cb3 hardware audio long tone
options snd_sof sof_debug=1
上記をしたら、ポータブックを再起動。
参照:sound - Audio crashes and loud tone from speakers - Ask Ubuntu
キーボードの「¥」(円マーク)キーと「\」(バックスラッシュ)キーの入力ができない。
適宜、mozcの辞書登録して対処しておくことに。
ここまででインストールは終了。以下はお好みで。
愛用のブラウザ Vivaldi をインストール。
Vivaldi をダウンロードから、Linux用のDebをダウンロード。
端末を開いて、
sudo apt install
と入力して(install の後には半角スペースを入れておく)、ダウンロードしたdebファイルを、ドラッグ・アンド・ドロップして、エンター。
後述のconkyやplankも含めた諸々のアプリをインストール。
sudo apt install gimp geany gufw pandoc conky-all plank
いろんな日本語フォントをインストール。
sudo apt install fonts-ipaexfont fonts-ipamj-mincho fonts-mplus fonts-kouzan-mouhitsu fonts-aoyagi-kouzan-t fonts-takao fonts-umeplus
後述のplank(軽量ドック)を使うために、デフォルトのパネルを上部へ。
portabook-conkyrc(Googleドライブの共有ファイル。)をダウンロードして、ユーザーフォルダ(/home/ユーザー名/)内に入れて、「.conkyrc」に名前を変える(「.」をつけると隠しファイルになってしまって見えなくなるけど、焦らないように。フォルダ内で右クリック>「隠しファイルの表示」にチェックを入れると見えるようになる)。
portabook-conkyrc(.conkyrcにリネームする)の中身は以下の通り。
conky.config = {
alignment = 'top_right',
background = true,
border_width = 1,
cpu_avg_samples = 2,
default_color = 'grey',
default_outline_color = 'grey',
default_shade_color = 'white',
double_buffer = true,
draw_borders = false,
draw_graph_borders = true,
draw_outline = false,
draw_shades = false,
use_xft = true,
font = 'UmePlus Gothic:size=10',
gap_x = 5,
gap_y = 38,
minimum_height = 5,
minimum_width = 5,
net_avg_samples = 2,
no_buffers = true,
out_to_console = false,
out_to_stderr = false,
extra_newline = false,
own_window = true,
own_window_class = 'Conky',
own_window_type = 'normal',
own_window_transparent = true,
own_window_argb_visual = true,
own_window_hints = 'undecorated,below,sticky,skip_taskbar,skip_pager',
stippled_borders = 0,
update_interval = 1.0,
uppercase = false,
use_spacer = 'none',
show_graph_scale = false,
show_graph_range = false
}
conky.text = [[
${color orange}OS:$color${execi -1 cat /etc/lsb-release | awk -F "\"" '{print $2}' | sed -n 4p}
${alignr}$sysname $kernel on $machine
${color orange}起動時間:${alignr}$color $uptime
${color grey}$hr
${color orange}Strage:$color/${alignr}${color orange}合計$color${fs_size /} ${color orange}使用$color${fs_used /} ${color orange}空き$color${fs_free /}
#/home ${alignr}${color orange}合計$color${fs_size /home} ${color orange}使用$color${fs_used /home} ${color orange}空き$color${fs_free /home}
${color grey}$hr
# ${color orange}SWAP:$color$swap/$swapmax - $swapperc%
# ${swapbar 4/}
# ${color orange}Frequency (in GHz):$color $freq_g
#${color orange}Processes:$color $processes ${color orange}Running:$color $running_processes
${color orange}CPU:${alignr}$color使用率$cpu%
#温度${execi 1 cat /sys/class/hwmon/hwmon0/temp?_input | awk '{printf("%.1f°C", ($1=$1 / 1000))}'}
# 上記でCPU温度が表示されない場合はこちらで。
#${color orange}CPU:${alignr}$color使用率$cpu% 温度${execi 1 cat /sys/class/thermal/thermal_zone0/temp | awk '{printf("%.1f°C", ($1=$1 / 1000))}'}
${cpubar 4/}
$cpugraph
${color orange}Name PID CPU% MEM%
${color lightgrey}${top name 1} ${top pid 1} ${top cpu 1} ${top mem 1}
${color lightgrey}${top name 2} ${top pid 2} ${top cpu 2} ${top mem 2}
${color lightgrey}${top name 3} ${top pid 3} ${top cpu 3} ${top mem 3}
${color lightgrey}${top name 4} ${top pid 4} ${top cpu 4} ${top mem 4}
${color grey}$hr
${color orange}RAM(メモリ):$color${alignr}$mem/$memmax - $memperc%
${membar 4/}
$memgraph
]]
以下の内容のスクリプト(startup.sh)をユーザーフォルダ(/home/ユーザー名/)内に作成。
#!/bin/bash
sleep 10
conky
plank
そのスクリプト(startup.sh)上で右クリックして、パーミッションのタブで「ファイルを実行可能にする」にチェックを入れる。
メニュー>設定>LXQt設定>セッション>自動起動>追加
で、
これで2027年(Lubuntu24.04のサポート期間)まで使える!

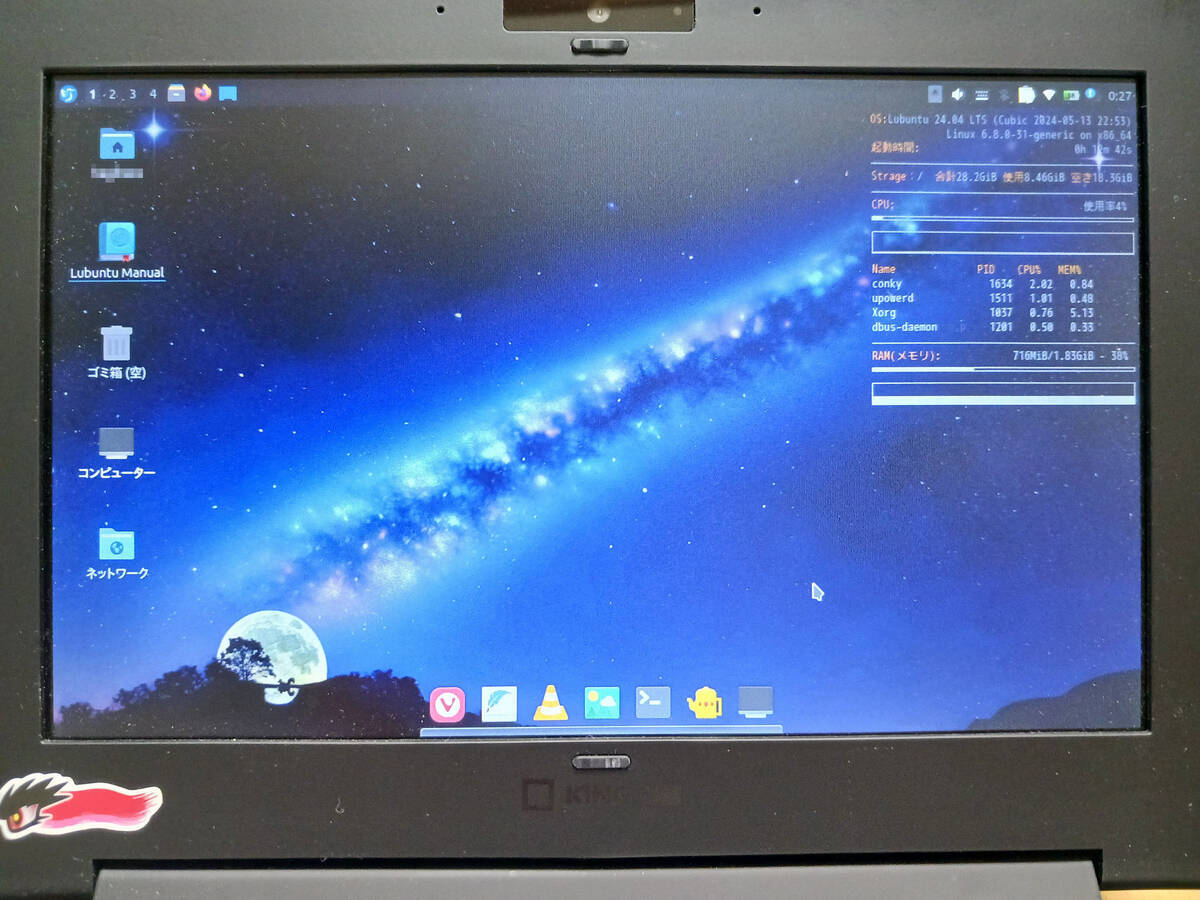
初めてスタイラスペンを買ってみた。替え芯等の備忘録。
三菱鉛筆 uni ジェットストリームスタイラス SXNT82_350-07
ぼちぼち更新していく。
公式のGitHub のREADMEのInstallationの「Linux: View Typst on Repology」にはUbuntuのレポジトリはない。
しかし、snapに入ってる。
sudo snap install typst
でインストール完了。
typst compile --font-path ~/.local/share/fonts/ test.typ
typst はシステム全体に入っているフォントしか拾ってくれないらしいので、--font-path ~/.local/share/fonts/でローカルに入っているフォントも認識してくれるようにする。
特定の箇所だけフォントサイズを変えたい場合。
#text(8pt)[このテキストだけ8ptになる。]
詳細はImage Function – Typst Documentationを参照のこと。
#figure(
image("image/桜島.jpg"),/*height:10emなどで画像の高さ調整*/
caption: [寺山公園から見える桜島#v(0.2em)], /* キャプション名と下の余白#v(○em) */
placement: auto, /* 画像位置 auto,top,bottom,none(その場) */
)<桜島> /*本文で参照する際のキーワード*/
↓別途、表の画像を作って、挿入する場合。
#figure(
table(
image("image/表の画像.png", height:11em), /*heightを調整して段組の行を揃える*/
stroke:none,
),
caption: [果物], /* キャプション名 */
supplement: [表], /*「Table」を「表」に。*/
gap:0.5em, /* キャプションと表との間 */
placement: auto, /* 位置 auto,top,bottom,none(その場) */
)<表b> /*本文で参照する際のキーワード*/
//「Figure」を「図」に。
#set figure(supplement: [図],)
本文中に「図1」などと入れる場合には、上記の「本文で参照する際のキーワード」を使い、本文で @桜島 などとすれば、自動で番号が付される。
Bibliography Function – Typst Documentationを参照のこと。
#bibliography("works.bib",title:"参考文献",style:"ieee")
GitHub - tudborg/notes.typ: Footnotes + Endnotes + Custom notes for Typst typesetting.からダウンロード(Code>Download ZIP をダウンロード)してきた notes.typ をコンパイルするファイルのあるディレクトリの中に入れる。
プリアンブルに
#import "notes.typ": note, notes
と書く。
/*文末脚注*/
#set par(justify: true,leading: 0.65em,first-line-indent: 0pt,)
#v(2em)*注*#v(-0.7em)
#notes()
/*文末脚注*/
以前、以下のような記事を書いたが、この方法だと別途「ページ番号.pdf」と「bookmarks.txt」が必要だった。
python と pdftk でPDFを結合し、ページ番号をつけ、しおりをつけるスクリプト - adbird(広告鳥) 備忘録
今回は、「ページ番号.pdf」と「bookmarks.txt」を用意しなくても良い方法。
えぇ、今回もChat GPTさんに聞きまくりました(これやるにはどんなスクリプト書けばいい?→こうです→こんなエラーが出たよ→こうでした→こんなエラーが…の繰り返し)。
環境はUbuntu。
├── 001_test.pdf
├── 002_テスト.pdf
├── 003_てすと.pdf
├── addbookmarks.py
├── getpagenum.py
└── mergepdf.py
pdfファイル名は「001_」というように、3ケタの連番+半角アンダーバーを必ずつける。
getpagenum.py、mergepdf.py、addbookmarks.pyの順番にスクリプトを実行していく。
pdfファイルを結合した際の、各pdfがどのページに位置づけられるかを取得。また、ファイル名を取得してbookmarks.csvに出力するスクリプト。
import csv
import glob
from PyPDF4 import PdfFileReader
# PDFファイルのリストを取得する
pdf_files = sorted(glob.glob("*.pdf"))
# 結合後の各PDFファイルの開始ページを取得する
start_pages = []
current_page = 1
for pdf_file in pdf_files:
with open(pdf_file, "rb") as f:
reader = PdfFileReader(f)
start_pages.append(current_page)
current_page += reader.numPages
# bookmarks.csvファイルに出力する
csv_file = "bookmarks.csv"
with open(csv_file, mode='w', newline='') as f:
writer = csv.writer(f)
for idx, start_page in enumerate(start_pages):
writer.writerow([f"1",pdf_files[idx], start_page])
print(f"CSVファイル '{csv_file}' に出力しました。")
端末で
python3 getpagenum.py
とすると、「bookmarks.csv」が生成される。
PDFの結合とページ番号の追加。
import os
import io
from PyPDF4 import PdfFileMerger, PdfFileReader, PdfFileWriter
from reportlab.pdfgen import canvas
# カレントディレクトリを取得
current_directory = os.getcwd()
# 結合後のPDFファイル名
output_pdf = os.path.join(current_directory, "input.pdf")
# ワイルドカードを使用してPDFファイルをリストアップし、ファイル名のソートを行う
pdf_files = sorted([os.path.join(current_directory, file) for file in os.listdir(current_directory) if file.endswith('.pdf')])
# PdfFileMergerオブジェクトを作成
pdf_merger = PdfFileMerger()
# PDFファイルを結合
for pdf_file in pdf_files:
with open(pdf_file, 'rb') as file:
pdf_merger.append(file)
# 結合したPDFを一時的なファイルに保存
temp_merged_pdf = os.path.join(current_directory, "temp_merged_file.pdf")
with open(temp_merged_pdf, 'wb') as file:
pdf_merger.write(file)
# ページ番号を追加する関数
def add_page_numbers(input_pdf, output_pdf):
with open(input_pdf, 'rb') as file:
pdf_reader = PdfFileReader(file)
pdf_writer = PdfFileWriter()
# 全ページの数を取得
num_pages = pdf_reader.numPages
# ページ番号を追加して新しいPDFを作成
for page_number in range(num_pages):
page = pdf_reader.getPage(page_number)
packet = io.BytesIO()
can = canvas.Canvas(packet)
text = str(page_number + 1)
can.drawString(565, 810, text) #ページ番号の位置(左下からの位置。単位はpt。)
can.save()
packet.seek(0)
new_page = PdfFileReader(packet)
page.mergePage(new_page.getPage(0))
pdf_writer.addPage(page)
# 新しいPDFを保存
with open(output_pdf, 'wb') as output_file:
pdf_writer.write(output_file)
# ページ番号を追加
add_page_numbers(temp_merged_pdf, output_pdf)
# 一時的な結合ファイルを削除
os.remove(temp_merged_pdf)
print("PDFの結合とページ番号の追加が完了しました。")
端末で
python3 mergepdf.py
とすると、「input.pdf」が生成される。Windowsは python3 ではなく、python かも(以下、同じ)。
bookmarks.csv 中の、ファイル名=ブックマーク名の「001_」から「050_」までの連番を削除。
bookmarks.csvをpdftkのブックマーク書式に変換して、上記のinput.pdfにブックマークをつけて、output.pdfに出力。
import csv
import re
import subprocess
# ファイル名
input_file = 'bookmarks.csv'
output_file_txt = 'output.txt'
output_file_pdf = 'output.pdf'
# ブックマーク書式のテンプレート
bookmark_template = "BookmarkBegin\nBookmarkTitle: {title}\nBookmarkLevel: 1\nBookmarkPageNumber: {page}\n"
# 連番のパターン
number_pattern = r'\d{3}_'
# 連番の最大値
max_number = 50
# CSVファイルの読み込み
with open(input_file, 'r', newline='', encoding='utf-8') as csv_in:
reader = csv.reader(csv_in)
# ブックマーク書き出し用のテキストファイルを作成
with open(output_file_txt, 'w', encoding='utf-8') as txt_out:
for row in reader:
# ファイル名から連番を削除
file_name = row[1]
# 連番を削除
file_name = re.sub(number_pattern, '', file_name)
# ページ番号
page_number = row[2]
# ページ番号が連番の最大値を超えている場合は調整
page_number = min(int(page_number), max_number)
# ブックマーク書式にフォーマットして書き出し
bookmark_data = bookmark_template.format(title=file_name, page=page_number)
txt_out.write(bookmark_data)
# pdftkを使ってPDFにブックマークを追加
subprocess.run(["pdftk", "input.pdf", "update_info_utf8", output_file_txt, "output", output_file_pdf, "verbose"])
print("処理が完了しました。")
端末で
python3 addbookmarks.py
とすると、「output.pdf」が生成される。完成。
ディレクトリ内にある複数のPDFファイル(001.pdf 002.pdf …などの連番のPDF)を結合して、通しページ番号をつけるpythonスクリプト。
Chat GPTさんに何度も聞きながら、できた。
何はともあれ、python をインストール。Ubuntu 22.04.3 LTS の場合、端末で
sudo apt install python3
PyPDF4をインストール。
pip install PyPDF4
結合させたい複数のpdfファイルの入っているディレクトリに、下記の内容の mergepdf.py を保存。
import os
import io
from PyPDF4 import PdfFileMerger, PdfFileReader, PdfFileWriter
from reportlab.pdfgen import canvas
# カレントディレクトリを取得
current_directory = os.getcwd()
# 結合後のPDFファイル名
output_pdf = os.path.join(current_directory, "output.pdf")
# ワイルドカードを使用してPDFファイルをリストアップし、ファイル名のソートを行う
pdf_files = sorted([os.path.join(current_directory, file) for file in os.listdir(current_directory) if file.endswith('.pdf')])
# PdfFileMergerオブジェクトを作成
pdf_merger = PdfFileMerger()
# PDFファイルを結合
for pdf_file in pdf_files:
with open(pdf_file, 'rb') as file:
pdf_merger.append(file)
# 結合したPDFを一時的なファイルに保存
temp_merged_pdf = os.path.join(current_directory, "temp_merged_file.pdf")
with open(temp_merged_pdf, 'wb') as file:
pdf_merger.write(file)
# ページ番号を追加する関数
def add_page_numbers(input_pdf, output_pdf):
with open(input_pdf, 'rb') as file:
pdf_reader = PdfFileReader(file)
pdf_writer = PdfFileWriter()
# 全ページの数を取得
num_pages = pdf_reader.numPages
# ページ番号を追加して新しいPDFを作成
for page_number in range(num_pages):
page = pdf_reader.getPage(page_number)
packet = io.BytesIO()
can = canvas.Canvas(packet)
text = str(page_number + 1)
# フォントを設定
# can.setFont('Helvetica', 12) # フォント名とフォントサイズ
can.setFont('Times-Roman', 12) # フォント名とフォントサイズ
# can.drawString(565, 810, text) #ページ番号が右上(左下からの位置。単位はpt。)
can.drawString(293, 25, text) #ページ番号中央下(左下からの位置。単位はpt。)
can.save()
packet.seek(0)
new_page = PdfFileReader(packet)
page.mergePage(new_page.getPage(0))
pdf_writer.addPage(page)
# 新しいPDFを保存
with open(output_pdf, 'wb') as output_file:
pdf_writer.write(output_file)
# ページ番号を追加
add_page_numbers(temp_merged_pdf, output_pdf)
# 一時的な結合ファイルを削除
os.remove(temp_merged_pdf)
print("PDFの結合とページ番号の追加が完了しました。")
※「can.drawString(293, 25, text) #ページ番号の位置(左下からの位置。単位はpt。)」の箇所は適宜、変更する。
pdfの入っているディレクトリで右クリック>端末で開く
python3 mergepdf.py
Windowsでは以下かも。
python mergepdf.py
Yahoo!ニュースのニュース動画やTVerの動画を、Linux(Ubuntu)のVivaldiで見ようとすると、推奨環境じゃないということで再生できない。
そんなときは、アドオンの拡張機能 User-Agent Switcher and Manager を使って、ブラウザをWindowsのChromeなどに偽装して視聴する。
上記アドオンのオプションで Custom Mode にして何も入力せず、そのままであればどのサイトでも設定したブラウザに偽装できる。
しかし、僕は積極的に「Linuxを使ってるんだぞ」とアピールしたいし、そういう人が多いほど、サイト構築者もLinuxユーザーを意識してくれるはず…?
ということで、 White-List Mode で、エラーで見られない動画等のサイトを入力して、 Save。
news.yahoo.co.jp, tver.jp
アドオンを入れたくない、という人はこちら。
環境はUbuntu 22.04.3 LTS。
端末で
$ crontab -e
最初はエディタ選択を求められるので、nanoを選択。
次のような行を入力。hogehogeの部分は適宜変更のこと。
土日も含めて毎日の場合。
#毎日6時
0 6 * * * DISPLAY=:0 smplayer "/home/hogehoge/ミュージック/目覚ましプレイリスト.m3u"
月曜日から金曜日の場合。
#月〜金の6時
0 6 * * 1-5 DISPLAY=:0 smplayer "/home/hogehoge/ミュージック/目覚ましプレイリスト.m3u"
月曜日から土曜日の場合。
#月〜土の6時
0 6 * * 1-6 DISPLAY=:0 smplayer "/home/hogehoge/ミュージック/目覚ましプレイリスト.m3u"
crontabの書式は、
分 時 日 月 曜日 コマンド(やスクリプト)
crontabでググればもっと詳細な情報が出てくるので、それらを参考に。